
요청서 작성의 허들을 낮추는 AI 요청서 설계기 : Embedding, Vector Search, 그리고 LLM
1. 개요
1.1. 들어가며
안녕하세요. 숨고 Backend Engineer Andrew, Data Scientist Bailey입니다.
AI 요청서는 기존의 요청서 작성 방식을 개선하고 고객이 더 간편하게 요청서를 작성하게 만들자는 목적을 달성하기 위한 기능으로, LLM (Large Language Model)을 활용해 요청서 작성 과정을 줄여서 요청서 작성 전환율을 높이고자 진행했던 프로젝트였습니다.
기존에는 고객이 원하는 서비스를 직접 선택한 뒤, 각 질문에 하나씩 답변해야 했습니다. 하지만 저희는 고객이 “매주 토요일 1회, 2시간씩 오후 1시부터 7시 사이에 영어 과외를 받고 싶습니다.” 처럼 자연어로 원하는 내용을 작성하면, AI가 이를 바탕으로 가장 적절한 서비스를 추천하고 요청서 질문의 답변을 자동으로 채워주는 경험을 제공하고자 했습니다.
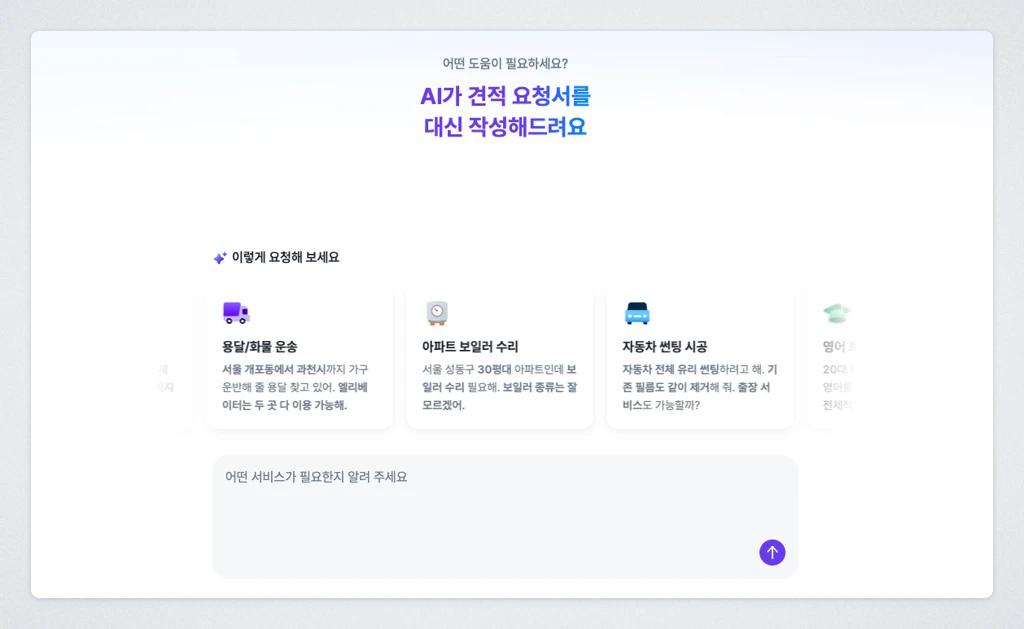
1.2. 요구사항
숨고의 서비스 요청 과정은 고객이 원하는 고수를 만나기 위한 첫 단계입니다. 하지만 기존 방식에서는 고객이 각 질문에 대해 라디오 버튼 (Radio Button), 체크박스 (Checkbox) 등 UI를 통해 답변을 하나씩 선택해야 했습니다.
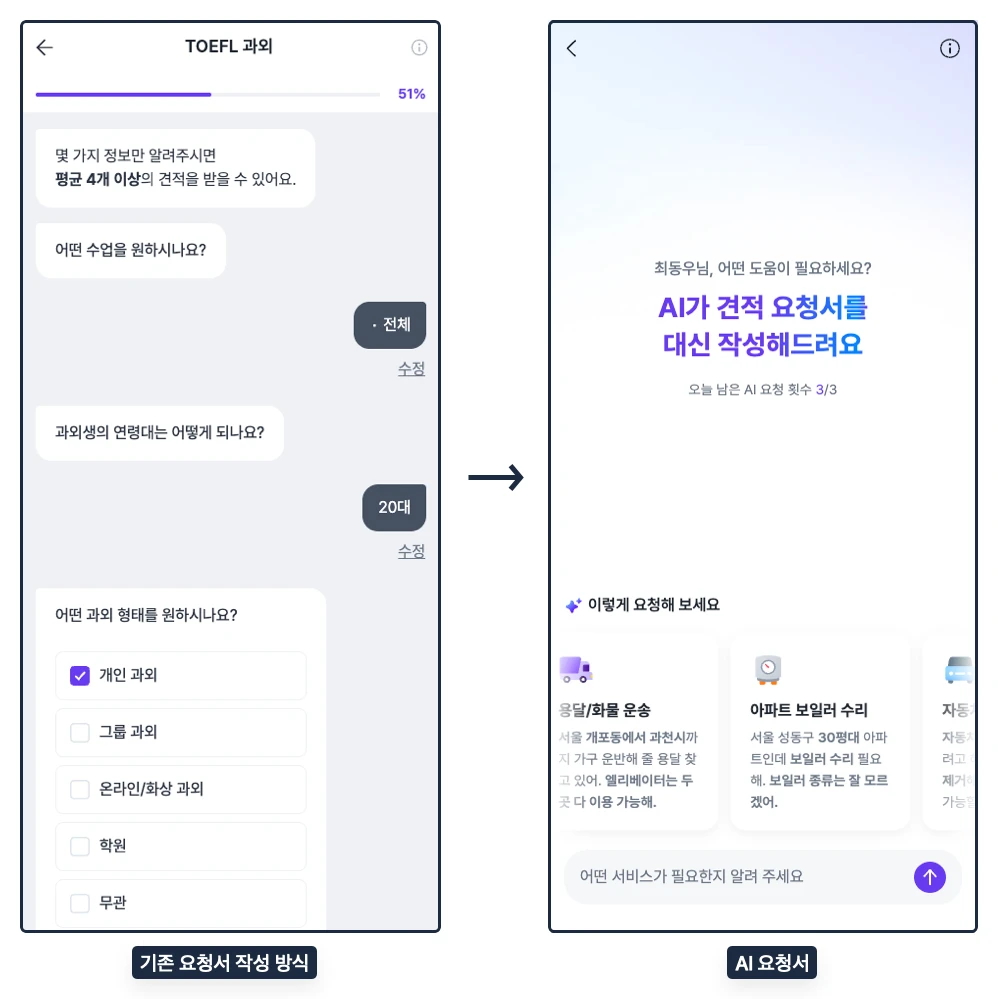
- 고객이 요청서를 작성할 서비스를 선택 (예 : 영어 과외)
- 서비스에 해당하는 요청서 질문을 순서대로 확인함 (예 : 영어 과외 서비스일 경우 "주 몇 회 과외를 받으실 건가요?")
- 각 질문에 맞는 답변을 선택함 (예 : 주 2회)
데이터 분석 결과, 질문의 개수가 많아질수록 고객 이탈률은 선형적으로 증가하는 패턴을 확인할 수 있었습니다. 고수를 만나기 위해 거쳐야 하는 '질답의 과정'이 오히려 서비스 진입의 허들이 되고 있었던 것입니다. 저희는 이 허들을 LLM을 활용해 낮춰보고자 했습니다.
기존 플로우 대신 한 번에 요청서를 작성하기 위한 경험을 제공하기 위해서는 아래와 같은 요구사항이 해결해야 했습니다.
- 고객이 작성한 내용을 기반으로 적절한 서비스가 선택되어야 한다
- 고객이 작성한 내용을 기반으로 적절한 답변이 요청서 질문에 매핑되어야 한다
이를 해결하기 위해 LLM을 활용한 '서비스 추천 모델'과 '요청서 자동 생성 모델'로 시스템을 나누어 구현했습니다.
2-Stage RAG 기반 서비스 추천 시스템 설계
이제 사용자의 자연어 입력을 특정 서비스로 정확히 매핑하기 위해 시스템 구조를 설계했던 과정을 소개하겠습니다.
2.1. 접근 방식 검토 : Fine-tuning vs RAG
가장 먼저 고민한 것은 ‘모델을 어떻게 구현할 것인가’였고, 초기에는 두 가지 접근 방식을 고려했고 결과적으로는 RAG 방식을 선택하였습니다.
| 항목 | Fine-tuning | RAG(Retrieval-Augmented Generation) |
|---|---|---|
| 기본 개념 | 모델 자체가 추천 능력을 학습 | 외부 데이터에서 후보 검색 후 LLM에 전달 |
| 비용 | 높음 (모델 자체 학습 및 추론 비용) | 낮음 (임베딩 + 검색 비용) |
| 업데이트 대응 | 서비스 추가, 변경 시 재학습 필요 | 벡터 DB에 추가만 하면 즉시 반영 가능 |
| 유지보수성 | 낮음 (무거운 학습 파이프라인 필요) | 높음 (데이터 중심 관리) |
| 추천 신뢰성 | 모델 내부 생성 (Hallucination 가능) | 실제 존재하는 데이터 기반 추천 |
RAG 방식의 선택 이유
1. 비용 효율성
| 항목 | 기본 모델(Gemini 2.5 Flash) | Fine-tuned 모델 |
|---|---|---|
| Input | $0.30 | $3.75 |
| Output | $2.50 | $15.00 |
| 배수 | 기준 | 약 5~12배 |
Fine-tuning은 모델 학습 비용뿐만 아니라 운영 단계의 추론 비용도 높습니다. 사용자 요청마다 LLM을 호출해야 하므로 트래픽에 비례해 토큰 비용이 누적되며, 월간 수천만 토큰이 발생하는 환경에서는 기본 모델 대비 수 배 이상의 비용이 발생할 수 있습니다.
반면 RAG 방식은 서비스 데이터를 사전에 임베딩하여 저장하고, 실제 LLM 호출 시에는 검색된 Top-K 후보만 제한적으로 전달합니다. 이를 통해 불필요한 토큰 사용을 방지하고 구조적으로 비용을 통제할 수 있습니다.
2. 유지보수성과 확장성
숨고 플랫폼의 1,000개 이상의 서비스는 지속적으로 추가되고 변경됩니다. Fine-tuning 방식은 서비스가 변경될 때마다 모델을 재학습하고 재배포해야 하므로 확장에 번거로움이 따릅니다.
반면 RAG는 ‘서비스 추가 → 임베딩 생성 → 벡터 DB 추가’의 단순한 흐름을 가집니다. 모델 자체를 변경하지 않고 벡터 데이터만 업데이트하면 프로덕션 환경에 즉시 반영할 수 있어 확장성이 뛰어납니다.
3. 추천 결과의 신뢰성
Fine-tuning 방식은 모델 내부의 확률을 기반으로 답변을 생성하기 때문에, 실제 존재하지 않는 서비스를 추천하는 환각 문제가 발생할 위험이 있습니다.
반면 RAG는 벡터 검색을 통해 실제 존재하는 서비스 후보를 먼저 선별한 뒤, 해당 후보만 LLM에 전달합니다. LLM의 생성 범위를 실제 데이터 안으로 제한하므로 오분류를 방지하고 추천 결과의 신뢰도를 높일 수 있습니다.
2.2. 단일 프롬프트 처리의 한계
RAG 채택 후, "전체 서비스 설명을 전부 LLM 프롬프트에 넣고 고르라고 하면 되지 않을까?"라는 아이디어도 검토했습니다. 하지만 이 방식에는 두 가지 치명적인 문제가 있었습니다.
- Latency와 비용 한계 : 1,000개가 넘는 메타데이터를 넣으면 수만 토큰이 발생하여 막대한 비용과 5초 이상의 응답 대기시간이 발생합니다.
- Attention Decay : LLM은 중간에 위치한 정보를 쉽게 놓치는 'Lost in the Middle' 현상을 겪습니다. 후보가 너무 많으면 모델이 엉뚱한 서비스를 매핑하는 빈도가 급증합니다.
이에 따라, 속도가 빠른 검색 모델을 전면에 배치해 후보군을 압축하는 2-Stage 퍼널 구조를 설계했습니다.
2.3. 1차 서비스 후보 생성(1,044개 → 100개 추출)
데이터 해상도 강화 및 Vector DB 도입
초기에는 '서비스명'만 임베딩했으나, 사용자는 "포장이사" 대신 "짐 옮겨주실 분"처럼 '상황'을 입력하는 경우가 많을 것으로 예상됐습니다. 이를 해결하기 위해 각 서비스의 실제 요청서의 질문과 답변을 분석하고, 서비스 수행 범위를 상세 문장으로 재구성해 임베딩했습니다.
첫 단계의 최우선 목표는 정답 누락 방지, 즉 재현율 (Recall) 확보였습니다. 1차에서 정답이 누락되면 복구가 불가능했기 때문에 핵심은 정확도가 아닌 **재현율(Recall)**이었습니다. 이에 한국어 환경에서 정답 포함률이 가장 높고 연산 속도가 빠른 한국어 특화 경량 Bi-Encoder 모델을 사용하여 100개의 후보를 추렸습니다.
이 모델을 선택한 이유는 다음과 같습니다.
- 한국어 특화 : 숨고의 서비스명과 사용자 입력은 모두 한국어이기 때문에 한국어에 최적화된 임베딩 모델이 필요했습니다
- 경량 모델 : 실시간 API 환경에서 사용해야 하므로, 인코딩 속도가 빠르면서도 충분한 품질을 제공하는 모델이 적합했습니다
- 정규화 지원 : 벡터 검색 시 코사인 유사도를 사용하기 위해
normalize_embeddings=True옵션으로 정규화된 벡터를 바로 얻을 수 있다는 점도 장점이었습니다
벡터 DB 인프라는 벤치마크 테스트를 거쳐 MongoDB Atlas Vector Search를 도입했습니다.
| 항목 | Qdrant | MongoDB Atlas |
|---|---|---|
| 1건당 평균 검색 시간 | 2.408초 | 3.115초 |
| 추천 정확도 | 97.87% | 97.87% |
| 인프라 구축, 운영 | 신규 클러스터 및 백업 체계 구축 필요 | 기존 MongoDB 운영 체계 그대로 활용 |
Hybrid Search 도입 : Vector Search에서 한 단계 더 나아가기
초기 구현에서는 순수한 Vector Search만을 사용했습니다. 사용자의 입력을 벡터로 변환하고, 사전에 임베딩해둔 서비스 벡터와의 코사인 유사도를 기반으로 후보 서비스를 검색하는 방식이었습니다. 하지만 특정 고유 명사나 전문 용어에 대해서는 기대만큼의 검색 성능을 보여주지 못했습니다.
예를 들어, "TOPIK 시험 준비"라는 입력에 대해 Vector Search는 "한국어능력시험" 서비스를 상위에 랭킹하지 못하는 경우가 있었습니다. 벡터 공간에서 "TOPIK"이라는 약어와 "한국어능력시험"이라는 정식 명칭의 의미적 거리가 충분히 가깝지 않았기 때문입니다.
이를 해결하기 위해 저희는 Hybrid Search를 도입했습니다. 의미 기반의 Vector Search에 단어 기반의 BM25 텍스트 검색을 병렬로 결합하는 방식입니다.
두 가지 검색 파이프라인
MongoDB Atlas의 Aggregation Pipeline을 활용하여, 의미 기반의 벡터 검색과 키워드 기반의 텍스트 검색을 병렬로 수행합니다.
1. 텍스트 검색(BM25)
- 검색 방식 : MongoDB Atlas Search를 활용한 BM25 기반 키워드 검색
- 대상 필드 :
service_name(서비스명),meta_description(메타 설명) - 특징 : 문서 내 키워드 출현 빈도 (TF, Term Frequency)와 전체 문서에서의 희소성(IDF, Inverse Document Frequency)을 기반으로 관련성 점수를 산출합니다. 사용자의 프롬프트를 그대로 쿼리로 사용하며, 'TOPIK'과 같은 고유 명사나 전문 용어의 정확한 매칭을 잡아내는 데 효과적입니다
2. 벡터 검색(kNN)
- 검색 방식 : Bi-Encoder로 생성한 프롬프트 벡터와 사전에 저장된 서비스 벡터 간의 유사도 검색
- 특징 : MongoDB Atlas Vector Search의
knnBeta연산자를 활용합니다. 1차적으로 300개의 후보를 넓게 검색한 뒤, 상위 100개로 제한하여 효율성을 높입니다
knnBeta: vector: {사용자 프롬프트 벡터} path: "vector" k: 300 // 1차적으로 300개 후보 검색 limit: 100 // 최종 100개로 제한
3. 점수 정규화 및 가중합(Score Normalization & Weighted Sum)
BM25 점수 (문서 길이 및 빈도에 따라 가변적)와 벡터 검색 점수 (0~1 사이의 코사인 유사도)는 스케일이 다르기 때문에, 단순 합산 시 스케일이 큰 쪽에 편향되는 문제가 발생합니다. 이를 방지하기 위해 점수 보정 과정을 거칩니다.
- Min-Max 정규화 : 두 검색의 점수를 동일한 [0, 1] 범위로 맞춥니다
normalized_score = (score - min_score) / (max_score - min_score) - 가중합 산출 : 정규화된 점수에 각각의 가중치를 적용하여 최종 점수를 계산합니다
final_score = (text_score × 0.3) + (vector_score × 0.7) - 가중치 설계 의도 : 서비스 추천의 핵심은 '사용자의 의도 파악'이므로 의미 기반인 벡터 검색에 더 높은 가중치 (0.7)를 부여했습니다. 텍스트 검색 (0.3)은 고유 명사나 전문 용어에 대한 정확한 매칭을 보완하는 용도로 활용됩니다.
계산된 최종 가중합 점수 (final_score)를 기준으로 정렬하여 상위 100개의 서비스 후보를 1차 결과로 응답합니다. 이 100개의 후보는 다음 단계인 Cross-Encoder 기반 Reranking의 입력값으로 전달됩니다.
2.4. 2차 정밀 타겟팅 : Cross-Encoder (100개 → 50개 선정)
1차로 추출한 100개의 후보는 문맥의 미묘한 의미 차이까지 정렬된 상태는 아닙니다. 이를 극복하고자 두 텍스트를 모델에 동시에 입력하여 직접적인 Self-Attention 연산을 수행하는 Cross-Encoder를 도입했습니다.
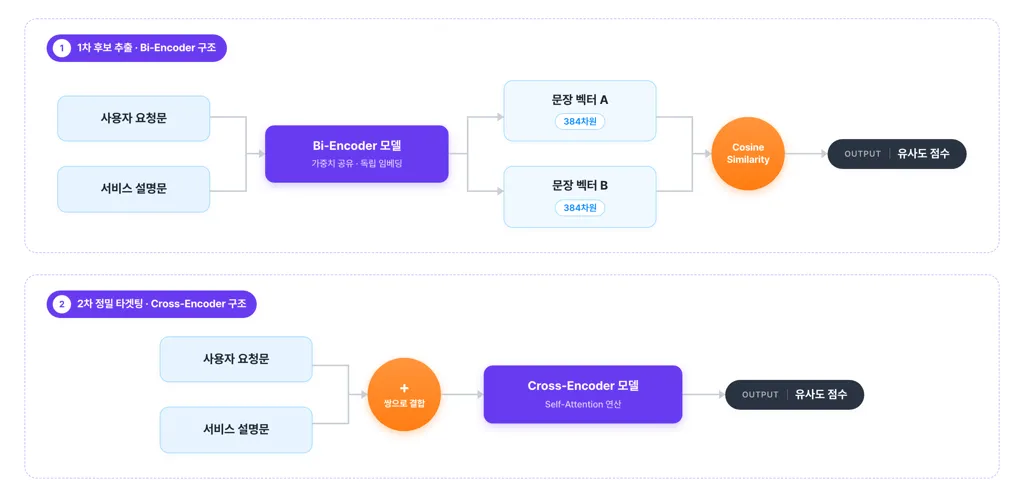
테스트 결과, 다국어 모델(BGE-M3)보다 숨고 도메인의 한국어 맥락을 잘 이해하는 리랭킹 모델을 최종 채택했습니다.
| 모델명 | 특징 | NDCG@10 |
|---|---|---|
| BGE-M3(Multilingual) | 다국어 지원, 범용성 우수 | 0.712 |
| 한국어 특화 리랭킹 모델 | 한국어 특화, 리랭킹 결과 우수 | 0.865 |
Threshold 설정 : 50개로 고정한 이유
Cross-Encoder를 거쳐 최종적으로 LLM에게 전달할 후보 수(K)를 결정할 때, 성능과 비용 사이의 트레이드 오프를 확인했습니다.
| K(최종 후보 수) | 정답 포함률(Recall) | LLM 최종 추천 정확도 | 특징 및 이슈 |
|---|---|---|---|
| Top 20 | 88.5% | 85.2% | 1차 선별군에서 정답이 누락되는 케이스 잦음 |
| Top 50 | 96.8% | 95.5% | 비용, 성능 최적점(Elbow Point) |
| Top 100 | 98.2% | 90.1% | 정보 과다로 LLM 주의력 분산, 오답률 상승 |
K가 50보다 작으면 정답 자체가 누락되었고, 반대로 K를 100개 유지하면 LLM이 너무 많은 정보 탓에 엉뚱한 서비스를 매핑하는 경우가 많아졌습니다. 이에 최적의 Elbow point인 50개를 최종 임계값으로 고정했습니다.
2.5. 최종 추천 서비스 결정
Reranker는 단순한 '유사도' 측정기일 뿐, 사용자의 복잡한 제약 조건을 파악하지는 못합니다. (예 : "짐만 옮겨 주세요.") 따라서 압축된 50개 후보를 LLM에 전달하여 최종 판별했습니다.
특히 “천장 수리”처럼 유사하지만 완벽히 일치하지 않는 요청이 “집 수리”로 과도하게 확장되는 문제를 제어하기 위해, 프롬프트에 다음과 같은 분류 기준을 명확히 심었습니다.
detected: 요청자의 니즈를 완벽하게 제공할 수 있는 경우clarify: 요청자의 니즈 중 일부만 제공 가능하거나 포괄적 상위 카테고리인 경우invalid_request,not_found: 악의적 프롬프트, 제공 불가능한 요청 차단
3. 요청서 자동완성 구현 및 최적화
서비스가 추천되었다면, 이제 사용자가 작성한 자연어에서 해당 서비스의 상세 질문지(Radio, Checkbox 등) 답변을 채워야 합니다.
3.1. 모델 개발 방향 : Zero-shot 정보 추출
이 단계는 단순한 분류를 넘어 자연어 속에서 정보를 정확히 뽑아내는 정보 추출(Information Extraction) 태스크입니다. 서비스마다 질문의 스키마 (Schema)가 다르기 때문에, 해당 스키마 구조를 LLM에 컨텍스트로 제공하고 선택지 중 가장 적절한 값을 찾아 매핑하는 방식 (Schema-constrained Generation)으로 접근했습니다.
3.2. 주요 오류 제어 (Golden Rule)
초기 모델은 다음과 같은 문제를 보였습니다.
- Hallucination : 입력에 정보가 없는데 모델이 임의로 판단 (예 : 이사 날짜가 명시되지 않았는데 오늘 날짜로 응답 생성)
- 매핑 오류 : 의미는 유사하나 스키마에 정의되지 않은 임의의 텍스트로 옵션을 출력함
- 구조 파싱 에러 : 질문이 복잡할 경우 지정된 JSON 포맷을 깨뜨림
문제를 해결하기 위해 테스트 및 운영 과정에서 발생한 오답 케이스를 수집하고, 이를 방어하는 Golden Rule을 프롬프트에 지속적으로 주입했습니다.
- '입력에 없는 정보는 절대 유추하지 말고 반드시
null로 반환할 것'을 최우선 규칙으로 강제 - 질문 타입(단일 선택, 중복 선택)별 처리 방식을 명확화
- 확실하지 않을 경우 임의의 답변 대신 시스템이 후처리를 할 수 있도록 여지를 두게 함
아무리 프롬프트를 고도화해도 고객이 충분한 정보를 제공하지 않아 LLM이 응답을 못 하거나 예외가 발생할 수 있습니다. 이때 강제로 빈칸을 남기기보다는, 유저의 수정 피로도를 낮출 수 있는 결측치 대체 전략이 필요했습니다.
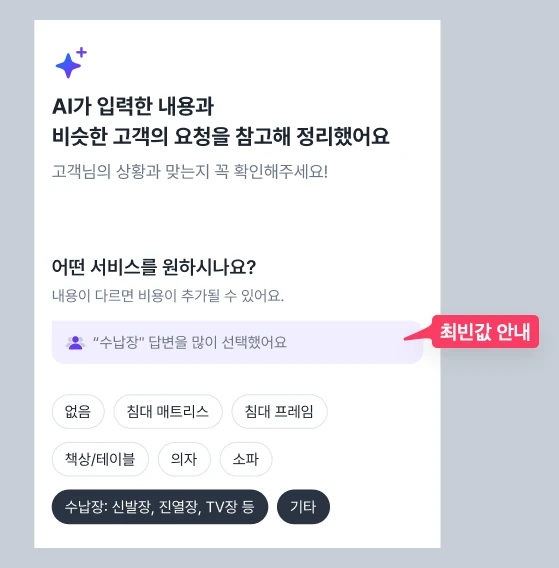
그래서 '최근 30일간 해당 서비스의 최빈값'을 활용해 빈칸을 채우는 Fallback 로직을 적용했습니다. 복잡한 추천 알고리즘 대신, 통계적으로 가장 무난하고 수요가 많은 디폴트 값을 제공하는 것이 현실적인 타협점이었습니다. 단, 데이터가 없는 신규 서비스의 Cold Start 상황에서는 강제 채움 없이 빈칸으로 두도록 설계했습니다.
3.4. Online 성과 분석 : AI는 얼마나 정확하게 대신 작성했을까
모델이 고객의 요구사항을 얼마나 잘 반영했는지 검증하기 위해 수정률을 측정했습니다. 즉, AI가 작성해준 답변을 고객이 그대로 수용했는지, 아니면 다시 수정했는지를 기준으로 모델 응답의 적절성을 검증했습니다.
- 최빈값(Fallback)으로 자동 작성된 항목의 수정률 : 28%
- AI 모델이 자연어를 기반으로 자동 작성한 항목의 수정률 : 9%
이 지표는 매우 고무적이었습니다. 고객 10명 중 9명 이상이 AI의 답변을 단 한 번의 수정 없이 그대로 수용했습니다. 단순 통계치(최빈값)로 채웠을 때보다 수정률이 19%p나 낮았다는 것은, 모델이 고객의 맥락과 의도를 명확히 이해하고 요청서 작성의 번거로움을 실질적으로 해결해주고 있음을 보여줍니다.
3.5. 시스템 최적화 : API 분리와 UX 마스킹

추천 모델과 자동완성 모델은 기능적 목적이 완전히 다릅니다. 초기엔 이 둘을 하나의 LLM 호출로 묶었으나, 5초 이상의 치명적인 지연시간(Latency)과 정확도 저하가 발생했습니다. 이에 따라 저희는 Multi-Model 아키텍처를 채택하여 API를 완전히 분리했습니다. 이러한 설계 덕분에, 무거운 추론 작업을 백그라운드로 숨기면서 고객이 느끼는 체감 대기시간을 크게 줄일 수 있었습니다.
4. 성능 이슈 및 개선
4.1. Cross-Encoder 성능 이슈
위와 같이 Cross-Encoder를 기반으로 Reranking을 순조롭게 구현하는 듯했습니다. 하지만 개발 환경으로 배포한 뒤 문제가 발생했습니다.
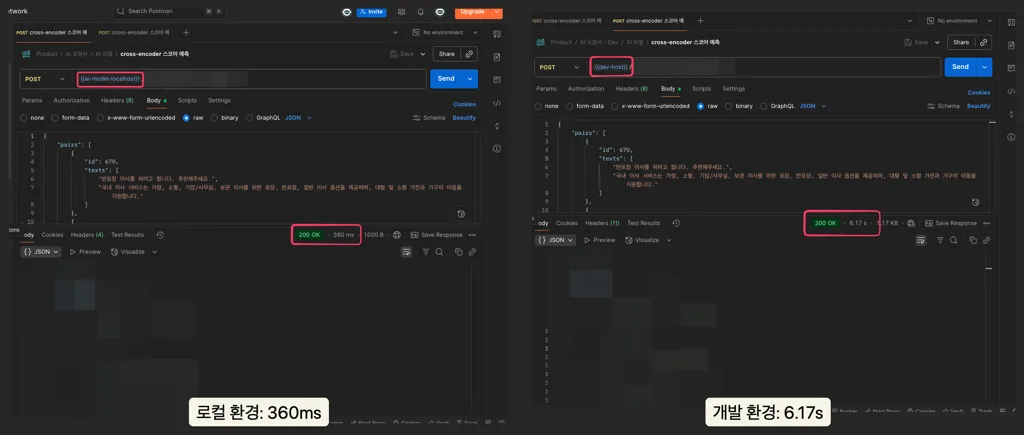
로컬에서 360ms 수준이던 Reranking 처리 시간이, 개발 환경에서는 6.17초로 약 17배 느려진 것이었습니다.
원인은 명확했습니다. 로컬에서는 머신에 탑재된 GPU로 모델 추론이 수행되었지만, 개발 서버의 컨테이너 환경에서는 CPU만으로 추론이 이뤄지고 있었습니다. Cross-Encoder는 (프롬프트, 서비스 설명) 쌍마다 전체 모델을 통과시키는 구조이므로, 100개 후보에 대해 유사도를 계산하는 과정에서 CPU의 한계가 그대로 드러난 것입니다.
서비스 추천 API 전체 응답 시간이 6초를 넘기는 것은 사용자 경험상 수용하기 어려운 수준이었기에, GPU 인스턴스 도입을 검토하게 되었습니다.
GPU 인스턴스 검토
AWS Inferentia
첫 번째 후보는 AWS의 자체 ML 추론 칩인 **Inferentia(inf1, inf2)**였습니다. Inferentia는 추론 워크로드에 최적화된 커스텀 칩으로, Nvidia GPU 대비 비용 효율성이 높다는 장점이 있습니다. 다만 Inferentia를 사용하려면 AWS Neuron SDK로 모델을 별도 컴파일해야 합니다. 저희가 사용하는 sentence_transformers 기반 Cross-Encoder를 Neuron 포맷으로 변환하고 호환성을 검증하는 과정이 추가로 필요했고, 무엇보다 모델을 교체할 때마다 컴파일 파이프라인을 다시 태워야 한다는 점이 도입을 미루게 한 결정적 요인이었습니다. 빠른 실험, 개선 사이클을 가져가야 하는 단계에서는 부담이 큰 제약이었습니다.
Nvidia GPU 인스턴스
두 번째 후보는 Nvidia GPU 기반 인스턴스였습니다. 추론 워크로드에 적합하고 sentence_transformers, PyTorch 생태계와의 호환성이 이미 검증되어 있어 별도의 모델 변환 없이 기존 코드를 그대로 사용할 수 있다는 점이 결정적이었고, 현재는 g6.xlarge 인스턴스를 사용하고 있습니다.
| 항목 | g6.xlarge |
|---|---|
| GPU | NVIDIA L4 1개 |
| vCPU | 4 |
| Memory | 16 GiB |
| GPU Memory | 24 GiB |
최종 해결 및 결과
DevOps 팀과 협업해 EKS 클러스터에 GPU 노드 그룹을 구성하고, AI 모델 서빙 파드를 GPU 노드에 배포했습니다. 그 결과, Cross-Encoder의 Reranking 처리 시간이 극적으로 개선되었습니다.
| 환경 | Cross-Encoder 처리 시간 |
|---|---|
| 로컬(GPU) | ~360ms |
| 개발 서버(CPU) | ~6,170ms |
| 개발 서버(GPU 적용 후) | ~300ms |
6초 이상 걸리던 처리가 300ms로, 약 20배 이상 개선되었습니다. 서비스 추천 API 전체 응답 시간도 약 3.6초 수준으로 안정화되어, 사용자 경험상 수용 가능한 범위에 도달했습니다.
5. LLM 평가 및 최종 모델 선정
5.1. 평가 데이터셋 구축 파이프라인
LLM 성능 평가를 위해 서비스 추천 5,400건, 자동완성 1,160건의 정답 세트를 구축했습니다. 외부 라벨링 업체를 활용했으나 품질 확보를 위해 내부적으로 2-Stage QA 파이프라인을 가동했습니다.
- Rule-based 검수 : 스키마 양식 오류 및 필수 필드 누락 1차 필터링
- LLM-as-a-Judge : 룰 기반으로 잡기 어려운 의미론적 오답은 GPT-4o를 판별자로 활용해 2차 검수
이 치열한 정제 과정을 통해 노이즈를 완벽히 배제한 신뢰도 높은 평가 환경을 마련했습니다.
5.2. 지표 분석 및 최종 선정 : '지시 이행력'이 승부를 갈랐다
| 평가 항목 | 모델 | 정확도(정답률) | 오답 (Hallucination) | 건당 비용 |
|---|---|---|---|---|
| 서비스 추천 | GPT-5-mini | 96.09% | 45건 | 2.7원 |
| Gemini 2.5 flash | 97.30% | 31건 | 2.5원 | |
| 요청서 자동완성 | GPT-5-mini | 95.08% | 409건 | 2.1원 |
| Gemini 2.5 flash | 95.77% | 345건 | 2.0원 |
수치적인 정확도 우위(95.77%)보다 결정적이었던 것은 모델의 보수적인 추론 성향이었습니다. 예를 들어, 알 수 없는 요청("22년식 타우러스슈퍼살롱")이 들어왔을 때 타 모델은 무리하게 유추하여 가상의 서비스를 생성하는 경우가 있었습니다. 반면 Gemini 2.5 flash는 우리가 명시한 ‘불확실하면 무리하게 추론하지 말고 null을 반환하라’는 규칙을 더 엄격하게 따랐습니다. 서비스 안정성이 최우선인 프로덕션 환경에서 이 특성은 매우 유리하게 작용하여 최종 모델로 선정되었습니다.
5.3. 추가 기능 : 모델을 활용한 추천 범위 확장
최종 도입된 AI 모델을 활용하여 다음과 같은 고도화된 추천 기능도 라이브 서비스에 적용했습니다.
- 확장 추천 : '기계식 키보드 윤활'과 같이 현재 명시적으로 존재하지 않는 서비스라도, 유사한 작업을 수행하는 '컴퓨터 수리' 전문가를 유연하게 매핑하여 추천
- 상황별 연관 추천 : '웨딩 촬영'과 같이 특정 목적을 위한 요청일 경우, 헤어, 메이크업, 헬퍼, 한복 대여 등 연관 서비스들을 패키지 형태로 포괄 제안하여 고객의 탐색 피로도를 덜어줍니다.
6. 마무리
'고객이 겪는 찰나의 불편함'을 해결하기 위해 시작된 AI 요청서 프로젝트는 단순한 기술 적용 프로젝트가 아닙니다. 1,044개의 방대한 서비스 속에서 가장 적합한 길을 찾기 위한 2-Stage RAG(Hybrid Search + Cross-Encoder) 아키텍처 설계, 비용과 성능 사이의 최적점을 찾는 실험, 데이터 노이즈를 걸러내는 파이프라인 구축. 이 모든 고민이 모여 실질적인 성과로 이어졌습니다.
"이삿짐 옮기고 에어컨도 달아주세요"라는 한 문장만으로 숨고의 서비스가 고객의 상황에 맞게 재구성되는 경험. 특히 어떤 서비스를 선택해야 할지 모르는 비회원 고객에게서, 검색 기반 진입점 평균 대비 +9.4%p 높은 전환 성과가 나타났습니다. 자연어 기반 안내가 탐색 부담을 줄이고 더 적절한 요청서로 연결하는 데 효과적이었음을 보여주는 결과입니다.
결국 AI 요청서는 기술을 적용하기 위한 프로젝트가 아니라, 숨고가 지향하는 쉽고 빠른 전문가 매칭이라는 본질에 더 가까이 다가가기 위한 시도였습니다. 그리고 이런 시도는 AI 요청서 하나에 그치지 않습니다. 고수가 자신의 강점을 더 잘 표현하도록 돕는 포트폴리오 작성 AI를 비롯해, 고객과 고수 양쪽의 경험을 다듬어줄 더 다양한 AI 기능들을 꾸준히 준비하고 있습니다. 앞으로도 숨고는, 고객이 원하는 전문가를 더 쉽게 만날 수 있도록 한 걸음씩 나아가려 합니다.
긴 글 읽어주셔서 감사합니다.
- #2-stage rag
- #ai
- #artificial intelligence
- #backend
- #data science
- #llm
- #rag
- #recommendation
- #soomgo




